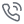数说故事
数说故事 2026-01-05
2026-01-05 10.6分钟
10.6分钟ACL大会由国际计算语言学协会主办,是自然语言处理与计算语言学领域最高级别的学术会议。ACL 2025是中国计算机学会(CCF)推荐的唯一A类的自然语言领域国际学术会议。
本次研究成果入选 ACL国际顶会,不仅是对「PARSQL」技术在轻量模型语义解析领域创新突破的国际认可,更是对数说故事与IDEA实验室产学研深度融合技术创新的肯定。

在企业数据量呈爆炸式增长的当下,数据洞察早已从「加分项」变成核心刚需。品牌投放反馈、大促期间流量瞬变、跨境市场&政策波动等场景,要求数据查询分析具备「秒级反馈」能力,如何让数据流动起来并创造价值?以往的Text‑to‑SQL(NL2SQL)技术,通过聊天的方式就能查询数据库,但实际使用时经常遇到尴尬问题:
常常漏掉关键约束。例如运营人员查询「近 30 天微博投放中互动率超 10% 且金额超 5 万」的内容时,模型因漏识 「金额」 条件致结果含大量低预算数据。
查询逻辑「翻车」。例如市场团队想获取「每个品牌在小红书平台的平均点赞数,并筛选出平均值大于1000的品牌」。模型误将筛选条件放到SELECT子句中,导致查询返回全量品牌数据而非目标品牌。
越复杂的业务需求,越「答非所问」。例如数据分析师查询 2024 年 Q1 连续三周产生爆文(点赞 > 1 万)的品牌并分析其投放频率周变化时,模型因未理解「连续三周」「爆文定义」「频率变化」复合逻辑仅返回所有爆文笔记,偏离分析目标。
本次论文中,双方合力研究的PARSQL(SQL解析与推理增强框架),直击 Text-to-SQL 技术在实际应用中的核心痛点,当面对复杂查询时,不是直接「硬闯」,而是先分析、再推理、最后生成,大大提升了准确性。本次研究中,我们将「PARSQL」技术的创新应用锚定在「轻量模型」上,让轻量级模型在资源受限环境下实现复杂语义解析、多条件关联查询的效率提升,开创低算力消耗的数据智能新路径。
01
「PARSQL」让轻量模型
也能应对复杂查询
相较于传统的 Text-to-SQL 「一步到位」转换模式,「PARSQL」创新性地拆解为「解析→增强→推理→校对」的四步策略,让轻量模型也能像资深数据分析师一样,系统化地理解和处理复杂的查询需求。
PARSQL的重要技术创新:解析+推理+选择
1
智能SQL解析
「PARSQL 」里的SQL解析器PARSer,能够先把 SQL 拆解成抽象语法树(AST),逐一提炼出用户在查询过程中的每个约束条件、子查询片段和关键节点。接着,「PARSQL 」会依照 SQL 的执行顺序来「讲故事」,从 FROM、WHERE 到 GROUP BY、HAVING,再到 ORDER BY,最后到SELECT,系统化地生成每一步的自然语言解释,为数据增强提供高质量训练样本。
2
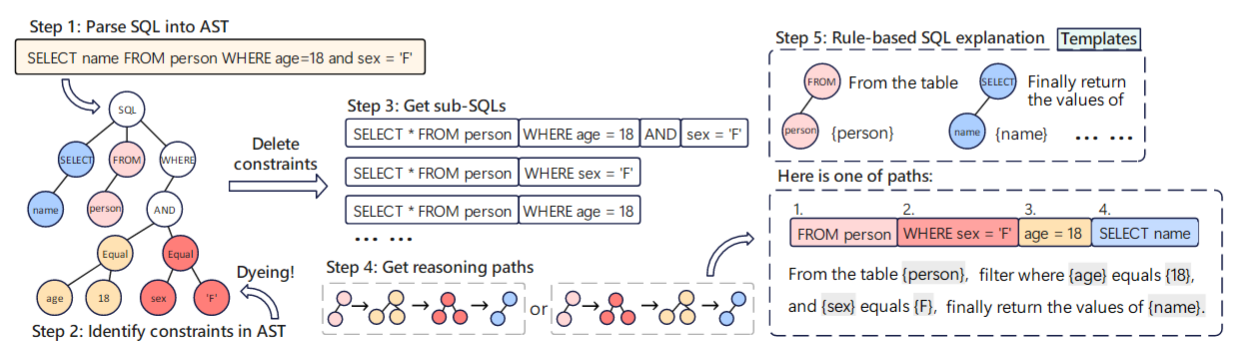
数据增强和多任务学习策略
「New Pairs」训练:将原始问题和 SQL 拆成只带部分约束的子对,从细节开始练起,让轻量模型在轻量级练习中敏锐捕捉细节;
「Reason Pairs」训练:让模型输出从问题到推理步骤的完整链路,学会写出「为什么这么查」,提升逻辑连贯性;
并行优化:同一次训练中,并行优化Text-to-SQL和Text-to-Reason两个任务,让模型既会写SQL,也会「说理由」。
3
高效选择策略
在推理阶段,PARSQL会生成多组候选SQL和对应的「推理脚本」,通过N-gram相似度计算,一秒钟内挑出最契合逻辑的那条。这种自我校正机制,把原本容易跑偏的「认知坑」填平。
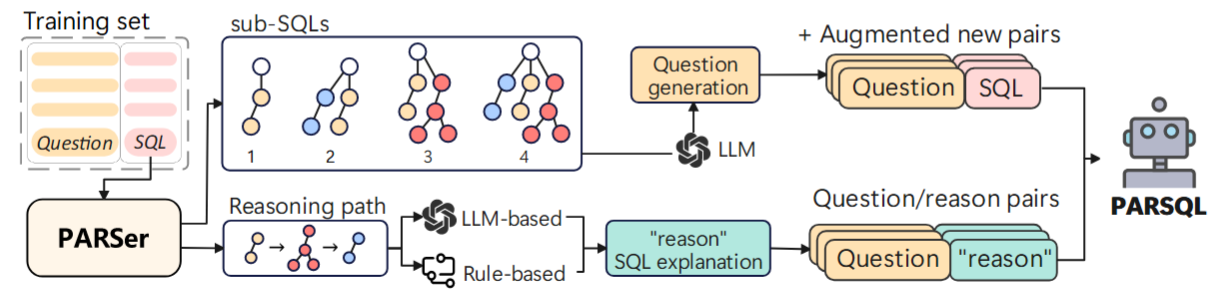
「PARSQL」技术已成功落地到数说故事旗下产品矩阵,以数说声呐产品的「智能问数」功能为例,业务人员可通过简答对话的形式便能实现自主数据探索。从业务的视角提出数据需求,「智能问数」能基于业务问题进行分析和解读,从数据中筛选准确的数据,进行合理的统计与总结,给用户明确的回答。
扫码咨询
更多应用和场景

02
性能突破:「PARSQL」
让轻量模型追平7B大模型
实验表明,与其他Text-to-SQL方法相比,「PARSQL」这样一套「解析→增强→校对」的组合拳,在多个基准数据集上展示了更高的准确性和更强的鲁棒性。
同等模型规模下表现更优:在 BIRD 数据集上,PARSQL rule 和 PARSQL llm 相较于 1B 和 3B参数规模下均优于 SFT CodeS。其中,PARSQL-3Bllm 比 SFT CodeS-3B 的 EX 分数提高了 1.96%,表现接近SFT CodeS-7B,意味着用更少的参数实现了相当的性能表现。
在通用数据集上更具竞争力:在Spider基准上,PARSQL-1B‑rule 相比 SFT CodeS‑1B 在执行准确率和语法正确性上分别提升 2.8% 和 2.6%,显著减少了小错误的产生,体现出其在基础任务中的稳定性和细节处理能力。
在复杂任务中更有潜力:在 BIRD 数据集上,PARSQL‑3B 相较于依赖 GPT‑4 的闭源方案,展现出相近的性能,说明在资源受限场景下,轻量模型仍具备良好的拓展潜力。


这意味着企业可以通过「PARSQL」技术,用更少的计算资源获得更高的查询准确性,大幅降低AI部署和运维成本,同时保证业务查询的精确性。当 AI 技术不再是「猛砸算力」,而是通过解析+推理+自我校正的多维度设计,就能让「小而美」的模型在千变万化的业务需求中游刃有余。
03
产业价值:重新定义
数据查询的「经济」模型
对于数据服务提供商和企业客户而言,「PARSQL」的技术突破具有重要的商业价值:
1、成本优化:轻量模型的资源消耗仅为大模型的几分之一,显著降低算力成本和部署门槛;
2、精度保证:通过SQL解析和推理机制,确保查询结果的准确性,避免业务决策偏;
3、本地部署:轻量模型更适合私有化部署,满足数据安全和隐私保护需求;
4、实时响应:更高的推理效率,支持高并发、低延时的查询场景;
随着「PARSQL」技术的产业化应用,将进一步降低企业数字化转型的技术门槛,让更多企业能够以更低成本、更高效率地利用数据价值,实现智能化决策。
未来,数说故事将继续秉承「用数据讲好商业故事」的使命,携手更多合作伙伴持续推动AI技术在数据服务领域的创新应用,为企业数字化转型提供更加智能、高效、经济的解决方案。
关于IDEA数说故事实验室
IDEA实验室 DataStory AI Lab由数说故事携手 IDEA实验室共建,基于数说故事“大数据+AI”丰富的技术栈积累和平台化能力,结合 IDEA实验室国际TOP50的超级计算集群优势,将联合国内外顶尖高校和科研院所,围绕AI知识图谱、下一代动态海量事理图谱技术等领域展开国际一流的研究和产业化落地。