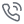“年纪轻轻,猫狗双全”正成为当代年轻人美好生活的最佳注脚。
近年来,“养宠大军”蓬勃壮大,宠物经济逆势大涨,“毛孩子”逐渐进阶为最重要的“家人”,“主子们”的日常用品也向人的消费习惯靠拢。在宠物食品方面,除了最基本的安全、健康,养宠人还对味道、功能、保健有一定要求。
面对养宠人的诉求升级,各大宠物食品品牌纷纷推出适口性和营养兼具的主食罐头、冻干、浓汤软包、肉条等。据数说故事旗下专业数据营销分析平台—数说千寻「趋势查询」显示,8月与“主食罐头”相关的笔记就有2w+篇,同比增长62.35%。
◎数说千寻-趋势查询
社交平台多方向赋能,针对宠物高品质喂养场景的需求,品牌如何通过内容营销实现赛道突围?数说故事通过拆解3个优质品牌的出圈案例,洞察宠物行业的营销趋势。
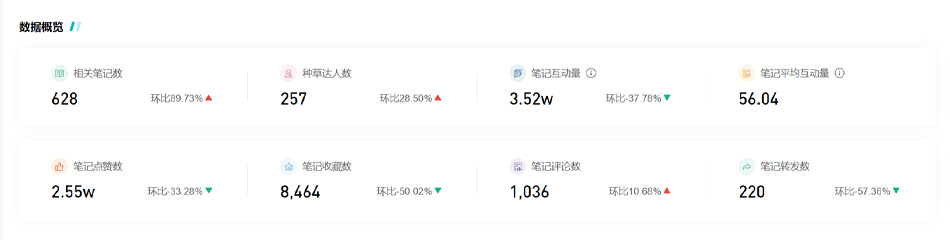
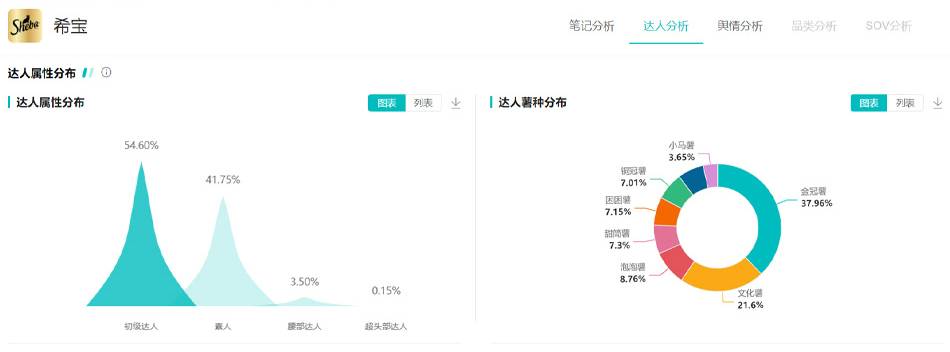
从品牌详情的「数据概览」报告来看,近30天“希宝”的种草数量和互动量都明显上升,共有628篇与品牌相关联的笔记,环比增长80.72%;笔记互动总量达2.81w,环比上升329.15%。超过60%的笔记含有罐头,主食,猫罐等关键词。
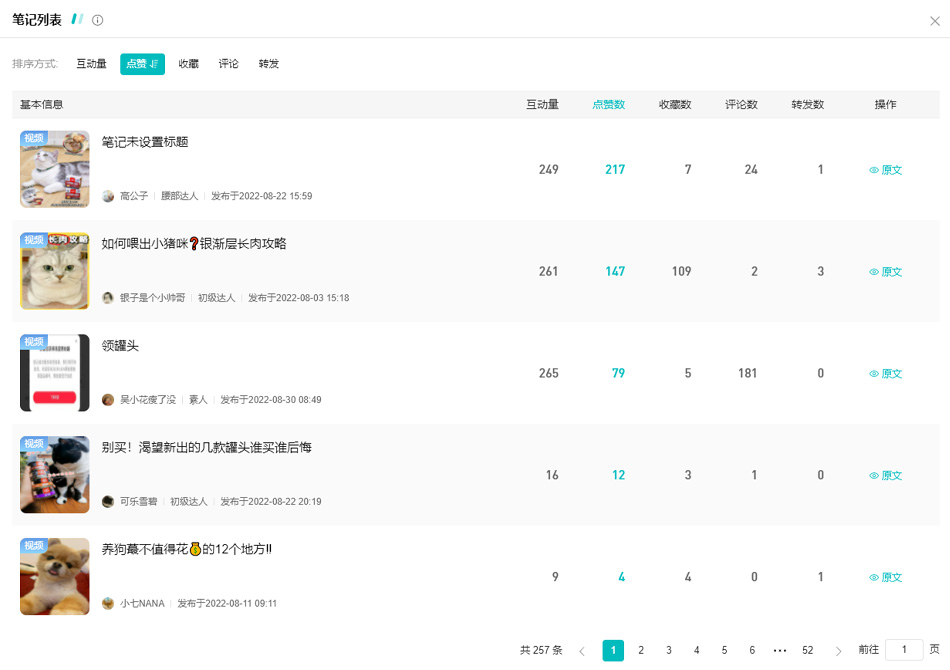
使用「趋势查询」功能以“猫罐头”“主食罐头”为关键词搜索近30天平台上所有的笔记内容与数据,按照笔记总互动量从高到低排序,TOP 10中,“希宝”商业投放的笔记占据4席。
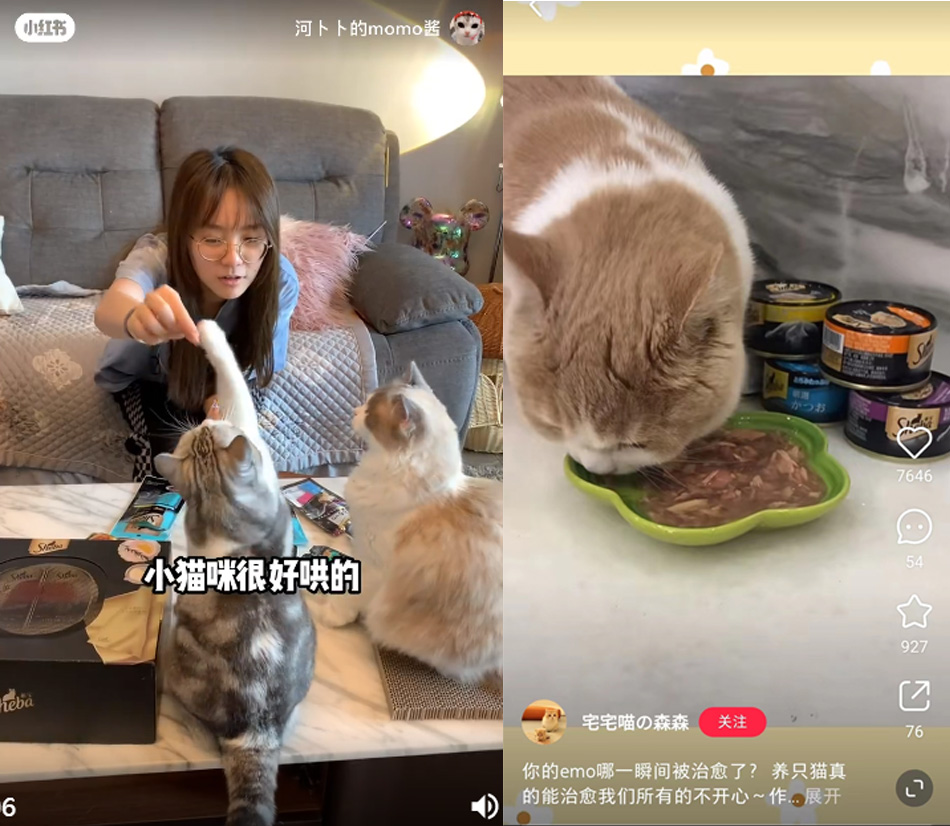
腰部达人@河卜卜的momo酱在视频中分享了自己独家的撩猫神器-希宝小魔盒,加上智趣的文案和配音、momo和卜卜的可爱出镜,获得互动2w+;@宅宅喵の森森以小猫咪在迎接养宠人回家、人宠互动玩耍、求养宠人陪伴睡觉时候的治愈猫叫声为切入点,在视频中植入产品,点赞量7000+;@黑猫荣华 则是分享猫主子干饭的趣照,通过可爱小猫咪舔罐头盖的动作,侧面点明希宝罐头的适口性高。
通过与多个腰部、初级宠物博主的联合种草造势,希宝在短时间内拉高了品牌在养宠圈的声量。以宠物的萌新短视频作为笔记的主要形式,成功聚焦了养宠人的目光,迅速提高了笔记的阅读量、互动量,抢占主食罐头赛道用户心智。
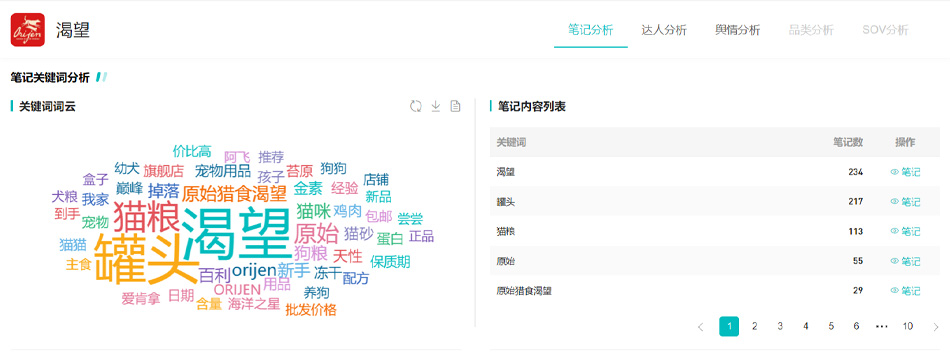
进口品牌“渴望”也在持续开展日常投放动作,为旗下的新品“原始罐”做推广。查看「笔记分析」的关键词词云和笔记内容列表发现,有217篇与“罐头”相关的笔记,占比12%,环比上涨2.5%。
查看【罐头】关键词下的笔记内容,数说故事洞悉到“渴望”投放的合作笔记在内容和形式上都与希宝有明显的差别,不走宠物卖萌+产品植入的短视频吸睛路子,而是通过图文的形式普及科学喂养知识+描述产品功能/优点+反馈宠物吃食后的表现,打造精细化内容矩阵。
时尚博主@高公子 作为资深铲屎官,先为粉丝普及了猫咪的食性和夏天高温天气喂食罐头的好处,再从自家猫主子爱吃渴望原始罐头引出含肉量高、肉质组成丰富、适口感好的产品优点,共获得217个粉丝点赞;@可乐雪碧 通过图文并茂详细列明渴望原始罐的成分、优点、功能,反向安利铲屎官们放心冲!放心买!
长图文的笔记形式缺少聚焦效应,无法短时间爆红。但干货分享、产品测评等优质笔记内容,能优先在搜索结果中展现,也更能打动寻找喂养方法的养宠新手,长期以往,达到为产品持续引流,提高产品在目标消费群体中的知名度和好感度,从而达到提升种草营销的销售转化率。
小红书平台上有超过1万个与萌宠相关的话题,其中#吸猫 的话题浏览量高达12亿,越来越多的人通过“云吸猫”“云撸狗”体验一把养宠的乐趣、在心中种下养宠的憧憬。相较于进口品牌还在致力于贴近养宠人,促进产品销售转化,国产宠物食品品牌更擅长破圈、更懂得如何在品牌上造势,实现品牌知名度在圈层上的飞跃,吸纳更多潜在养宠星人。
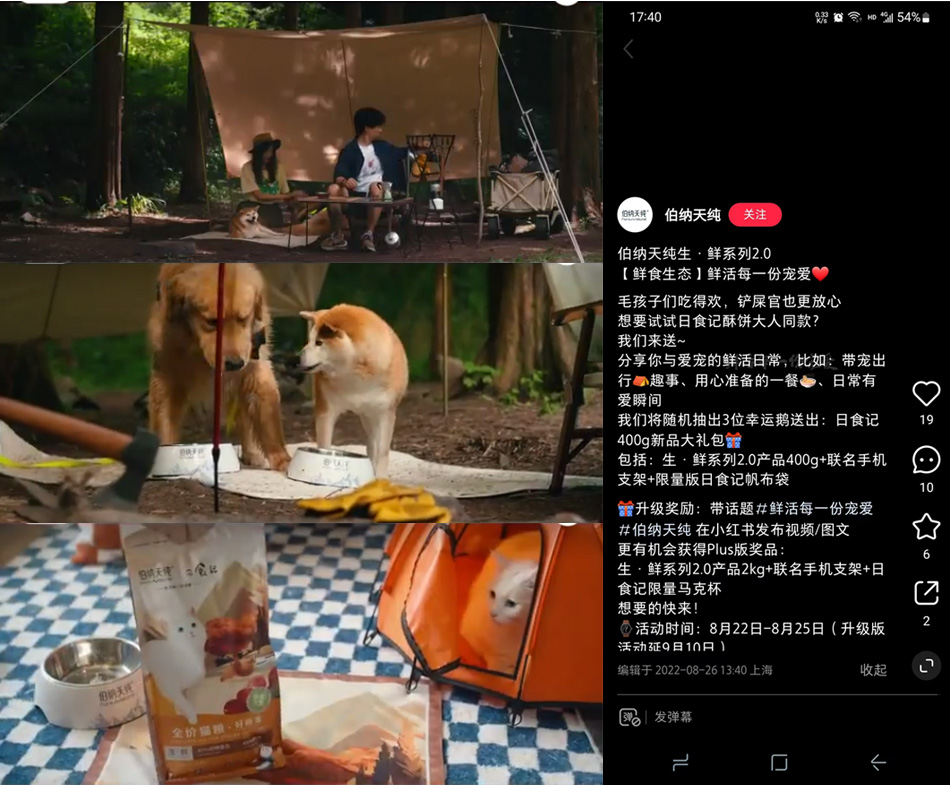
8月26日,@伯纳天纯品牌号官宣联手日食记推出生·鲜系列2.0宠物粮,并发布了最新的广告宣传片。全片记录了日食记博主与狗子酥饼露营的一天,通过真实喂养场景塑造了原料鲜活的产品印象,同时借助知名美食大V的影响力,成功打入美食圈。
与此同时,品牌方通过抽奖活动,带动了#鲜活每一份宠爱 #伯纳天纯的话题声量,「笔记趋势分析」图表显示,伯纳天纯在上周有一波较为集中的笔记投放,品牌总声量达388,互动量5000+,登上「火热品牌榜」第二位。
以上就是本期值得关注的品牌及其营销策略洞察,从上述案例中我们可以发现:
对于想要破圈纳新的品牌方来说,与头部大V或IP联名,能在短期内通过投放笔记、引爆热门话题、深度互动活动等方式快速打响品牌在其他圈层的知名度。
对于有高销售转化需求的品牌来说,与腰部达人、初级达人、素人合作,以产品优势卖点、产品功效、产品衍生玩法等角度打造精细化内容矩阵,触达搜索用户,长效引流。































 数说故事
数说故事 2026-01-07
2026-01-07 8.6分钟
8.6分钟