


爆款内容生成器?数说故事发布S-Library智能AI内容平台
发布时间:2020-11-18作者:DataStory
为什么B站的《后浪》能引起前浪和后浪的共同关注?
为什么"打工人"的梗可以迅速形成病毒式传播?
凡尔赛文学的魔幻魅力是什么?
让消费者找到共鸣,击中爽点,是这些爆款内容的成功法则。在注意力分散和信息碎片化的时代,用户几乎没什么耐心去仔细听一个品牌的广告讲故事,为了创作出既能迅速建立共情又能传递品牌信息的“故事”,无数广告创意人在深夜辗转反侧,在搜索引擎的海洋里寻找灵感,更有另辟蹊径者打开网易云/微博评论区发掘故事。
而现在,有这样一款产品——S-Library,它基于大数据和算法,智能输出故事素材,一起来看看它的神奇功能吧!👇
如何通过大数据
高效、高性价比地获取故事素材?
在S-Library输入“关键词”,一键搜索即可输出原始故事素材,进一步对故事进行标签化处理,按照“故事类型”和“Story Framework”对故事进行标签,通过“人设” 、“场景”、“感性诉求”、“理性诉求”、“品牌”、“产品”等类别,可以快速概览整个故事;最后通过算法计算综合得分,输出“有血有肉”的高质量故事。

在S-Library的背后,除了有监测整合各大社交媒体、新闻门户、垂直社区、视频故事、电商评论的大数据库,还有故事识别算法、Story Framework、故事打分模型,支持S-Library的语义搜索引擎、故事分析。
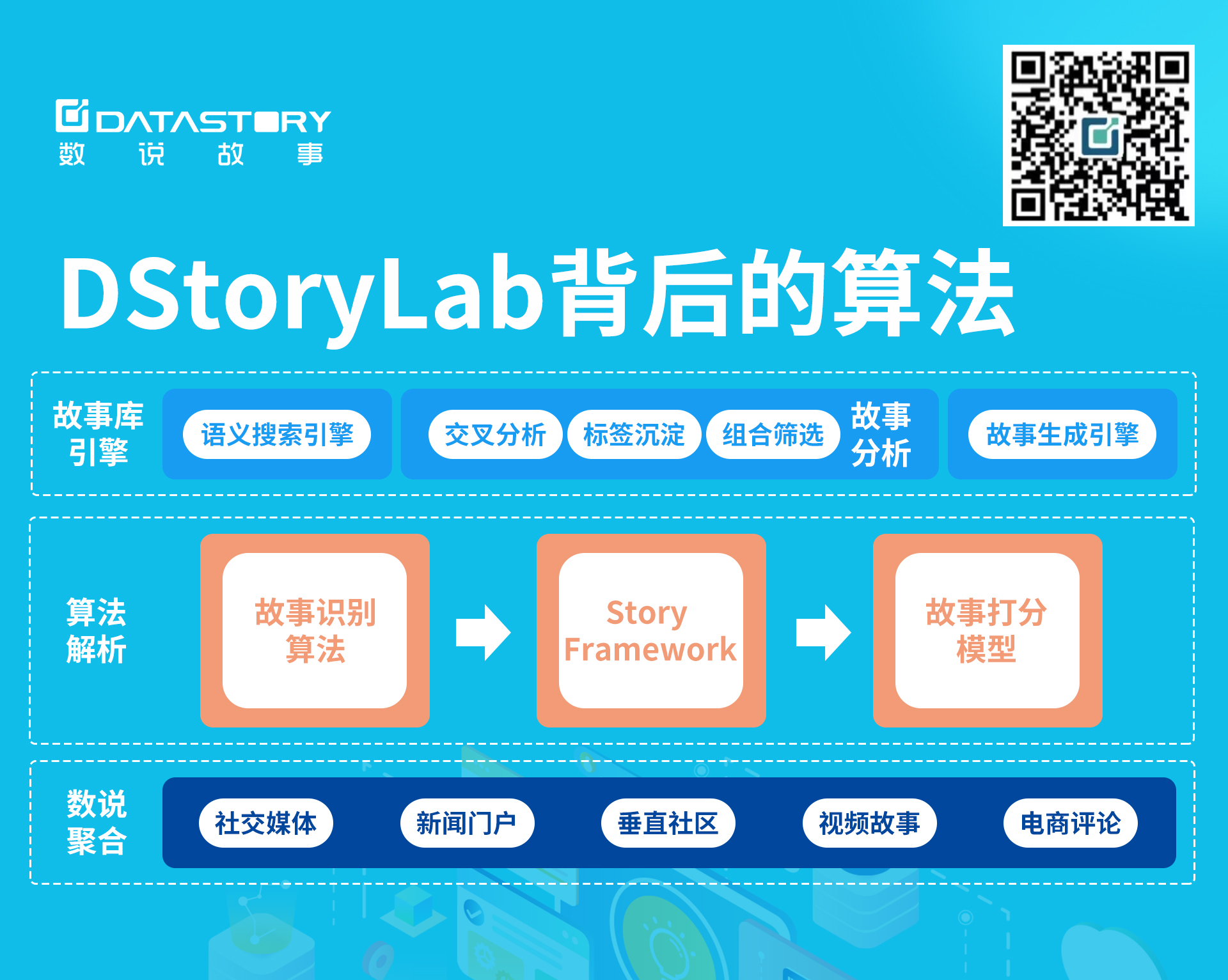
故事识别算法
为了让用户可以在S-Library快速搜索到想要的原始故事素材,算法是尤为关键的一环,数说故事的“故事识别算法”可以让语义搜索引擎变得更“聪明”,懂你所想。
以“一个焦虑新手宝妈宝爸的故事”这句话为例,“故事识别算法”可以自动抓取出“焦虑”、“新手”、“宝妈宝爸”这些关键词并进行模糊匹配,比如“焦虑”就会模糊匹配相近的一些负面情绪词,而“新手”则会模糊匹配类似于“没经验”一类的关键词,聪明的算法让用户在搜索时不再局限于自己所设置的关键词,输出更懂你更丰富的素材。

Story Framework
让我们来看看这段700字的育儿经验分享,像这样“有血有肉”的UGC内容,互联网上层出不穷,每日都在新鲜出炉。对内容洞察者来说,这样大段大段的文字需要他们花费大量时间阅读,才能提取有用信息,进而输出分析结果。
“Story Framework”按照“人设” 、“场景”、“诉求” 、“品牌”、“品类”、“痛点”、“情绪”等类别标签,拆解故事的逻辑和内容,它的作用就像是宴席前先帮厨师备好食材、切好、摆放整齐逐一归类;基于“Story Framework”,内容洞察者得以节省精力,归整所有相关的素材,输出精准的分析结果。

基于故事素材,层层剖析
输出人群洞察及沟通建议
基于故事素材,数说故事背后强大的分析师团队以“故事会四部曲”帮助品牌打通从“目标人群诉求”到“品牌主张切入”到“落地指导”的整个链路,S-Library绝不仅仅是内容素材这么简单👇
用户画像描绘
多维度立体展现目标人群所处的社会背景、关注点、所面临的主要冲突。
人群痛点深挖
情景还原目标人群主要冲突及欲望,解决方案,挖掘目标人群在不同场景/阶段的痛点及核心诉求。
品牌主张关联
围绕品牌精神和传播主题,建立“人群-品牌”的关联,筛选典型故事展示,输出品牌沟通切入点。
营销话题建议
结合人群研究及诉求探索,挖掘更多营销场景,分阶段,多维度提供传播话题规划和具体内容建议。
如需获取关于S-Library的完整版功能介绍及相关案例PPT,请扫码下方二维码填写信息👇


微信扫描二维码
微博扫描二维码

 Copyright © 2026 广州数说故事信息科技有限公司 All
Rights Reserved 版权所有 备案号:
粤ICP备15073179号
Copyright © 2026 广州数说故事信息科技有限公司 All
Rights Reserved 版权所有 备案号:
粤ICP备15073179号